Detección de Fraude en Tarjetas de Crédito
Modelo de clasificación para detectar transacciones fraudulentas en un dataset de 284.807 operaciones con un desbalance extremo de clases (0.17% fraudes). Modelo final LightGBM con umbral optimizado: detecta el 84.7% de los fraudes con solo un 0.03% de falsas alarmas.
El problema
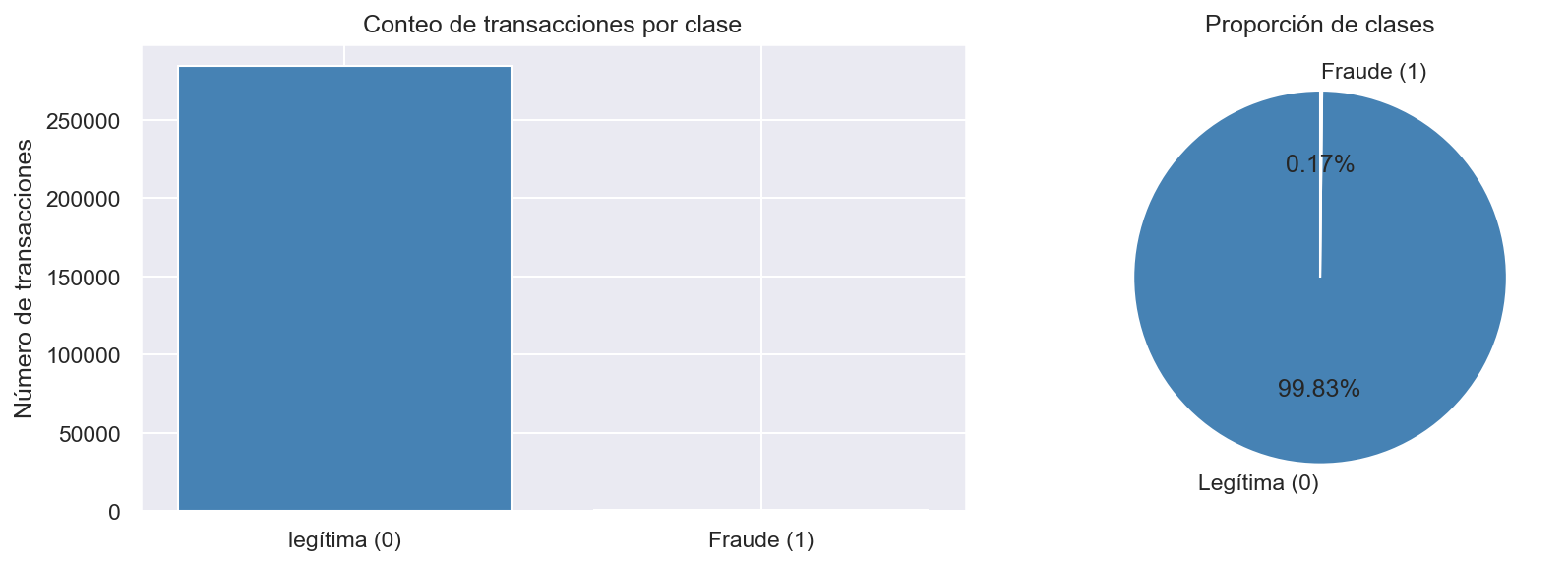
Las entidades financieras necesitan detectar transacciones fraudulentas en tiempo real sin generar un exceso de falsas alarmas que perjudiquen a los clientes legítimos. El reto principal es el desbalance extremo de clases: solo el 0.17% de las 284.807 transacciones son fraude, lo que hace que los modelos estándar fallen por completo al ignorar la clase minoritaria.
Proceso
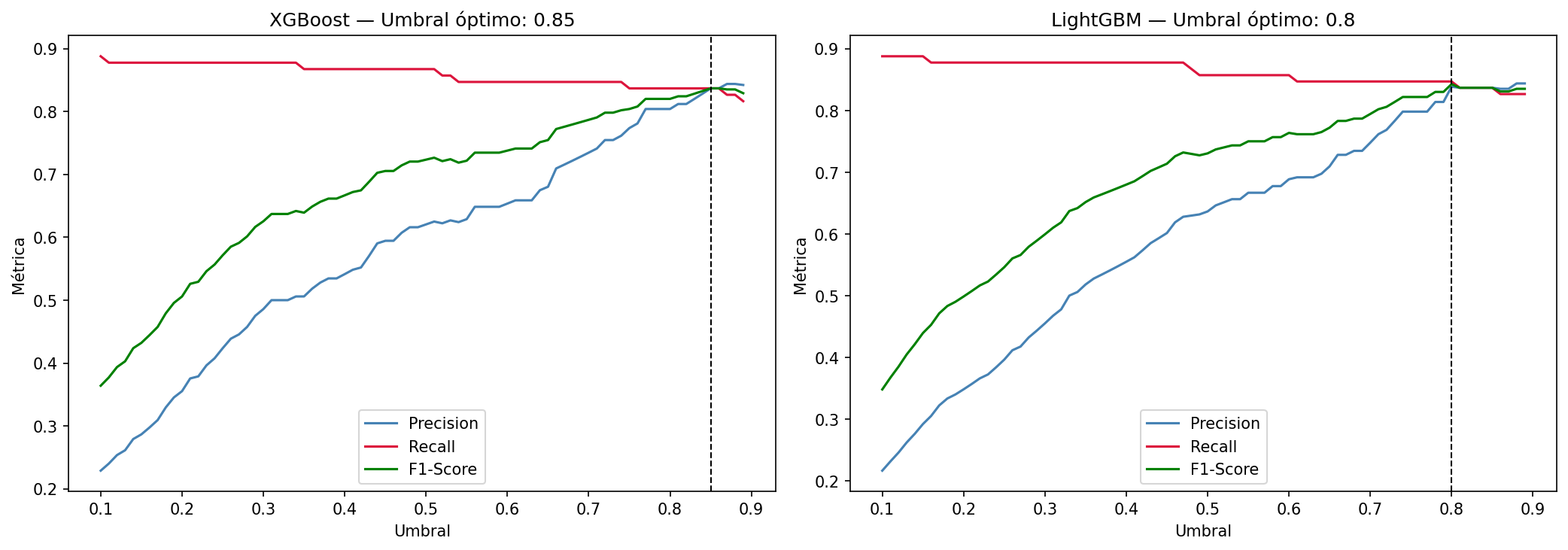
Se aplicó un pipeline estructurado en 4 fases. Primero, EDA para entender la distribución del desbalance, los importes y los patrones temporales del fraude. Segundo, preprocesamiento con split estratificado 80/20, escalado con RobustScaler y aplicación de SMOTE exclusivamente en train para evitar data leakage. Tercero, entrenamiento y comparativa de 4 modelos (Regresión Logística, Random Forest, XGBoost y LightGBM). Cuarto, threshold tuning para optimizar el equilibrio entre precisión y recall según el contexto de negocio.
Resultados
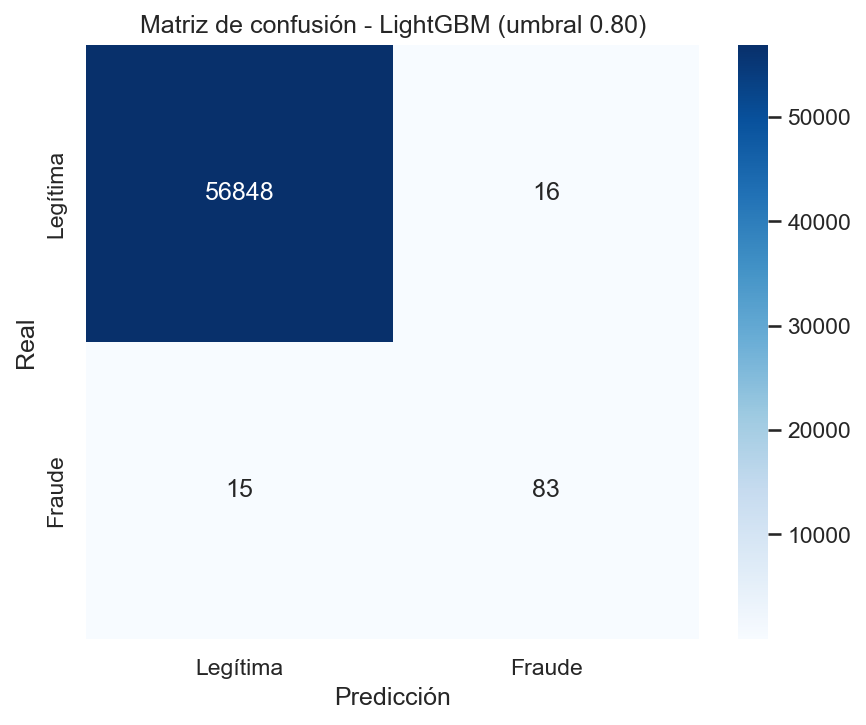
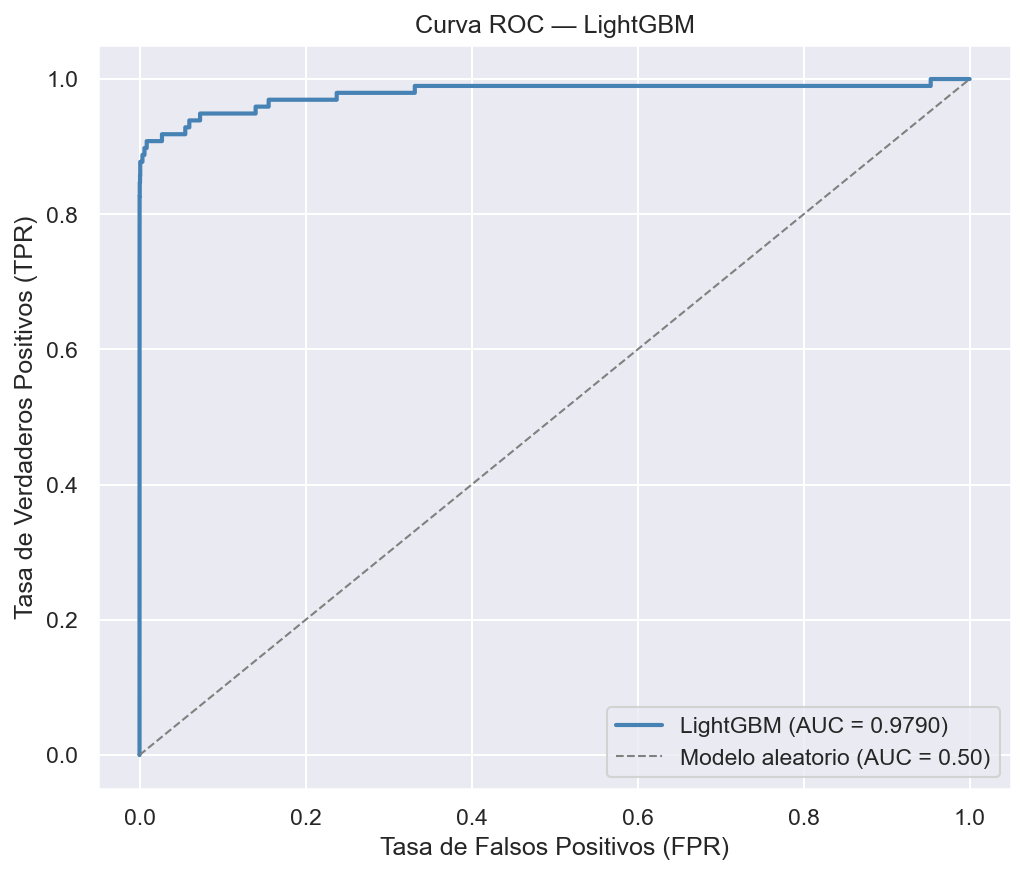
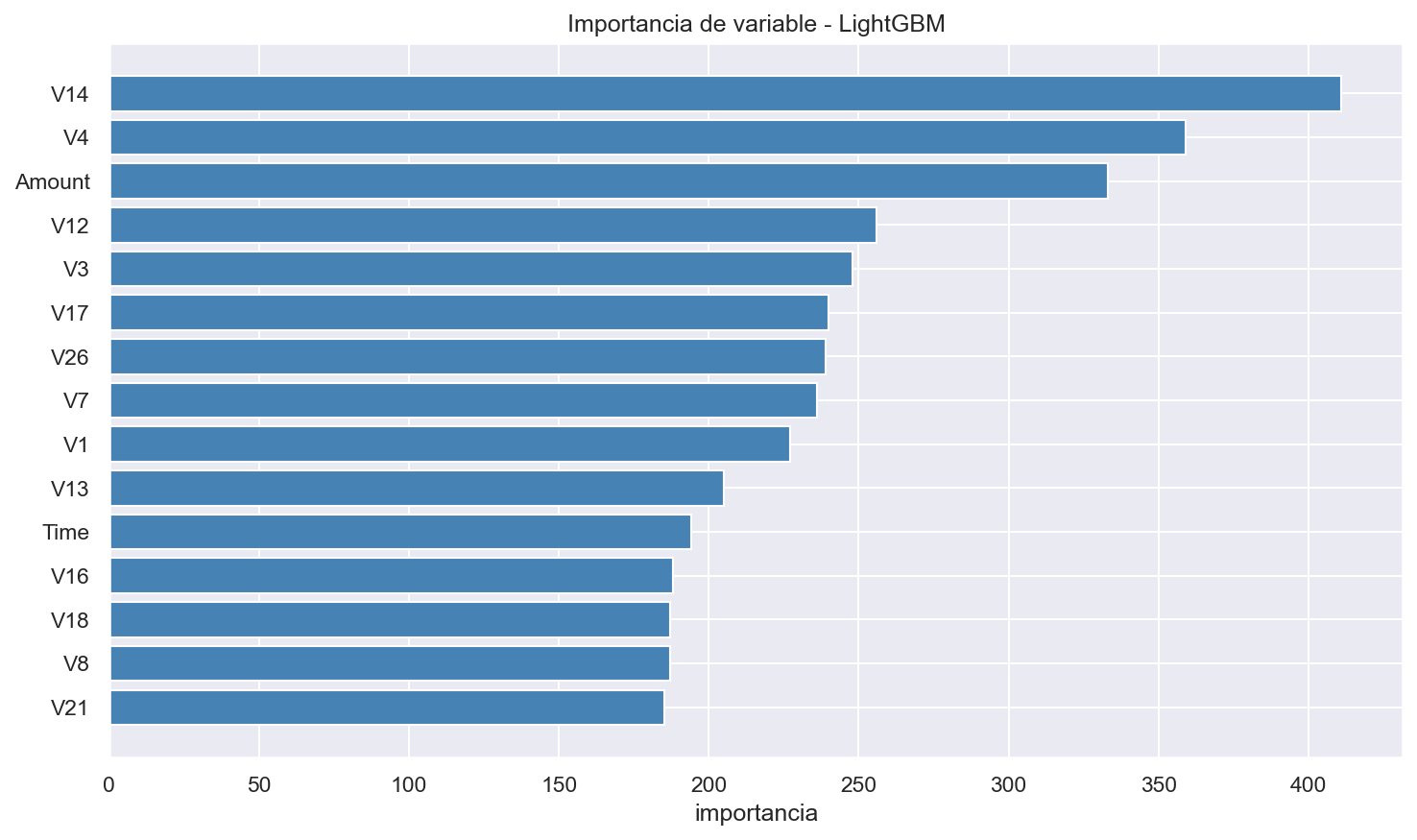
El modelo final LightGBM con umbral 0.80 alcanza un ROC-AUC de 0.979 y detecta 83 de los 98 fraudes reales del conjunto de test (84.7%), generando solo 16 falsas alarmas sobre 56.864 transacciones legítimas (0.03%). El Average Precision es 487 veces superior a un modelo aleatorio. Las variables más relevantes son V14, V4, Amount y V12.